


The Borlaug Report #6: Omics
The Companies Driving the Revolution in our Understanding of Science

Introduction
If you read my last few articles, you might be able to tell that I like the biologics industry. I’ve talked a lot about the existence of the megatrend toward complex molecules targeting wider ranges of disease, but not about what makes me so confident it persists (other than an extrapolation of the last 5-10 years of biotech macro data).
This time I’m writing about the innovation and tools that will likely be behind all of the major biologic drug discoveries ahead of us. What I’m hoping to accomplish is to lay out a primer on “omics”, a term coined to capture several categories of tools that analyze everything from genes to proteins.
The way we understand science is starting to inflect. It’s easy to think that pharma R&D will continue to get less and less efficient as more of the “low-hanging fruit” is picked. However, I’d assert that the way we understand biology has been getting several huge boosts over the last 5 years. If I’m right, a whole new orchard could be sprouting.
There is a lot of talk about all the fancy new things the biopharma industry is trying to do for sure; complex large molecules like Sarepta’s gene therapy for DMD look incredibly ambitious. What is less-appreciated, in my opinion, is how hamstrung we were until 3-5 years ago in terms of our ability to understand drivers of disease, and how that is changing. Today, we are finding new things to target, new ways to segment patient populations, and new ways to check if our drugs are working.
Separately, a lot of science is done in a very guess-and-check fashion - you practically throw a bunch of things at a wall and see what sticks in some cases. As such, the big bottleneck in the 2000s was the cost of doing these experiments in the first place. Expensive experiments limited the number of samples you could compare, and the number of times you could run follow-up experiments in a certain direction per year. We’ve made a lot of progress here.
Before I tell you about how the first human genome was sequenced in 2003, took over a decade, and cost over a billion dollars, it’s worth elaborating on what sequencing means. Sequencing is the conversion of a sample to useful data, akin to “reading”. In the case of genomics, it is converting a biological sample (tissue, blood, etc.) into a computer file with a long list of A’s, T’s, C’s, and G’s, which you probably learned about in middle school science class. That’s it! A fancy word to describe what is effectively just reading or interpreting something. The challenge has just been actually doing it at an affordable price.
That said, we’re kinda pulling it off! Thanks to industry breakthroughs, we got the cost of sequencing a human genome from $1B to $1k in 20 years without a competitive market. With competition emerging over the last five years, we’re down to about $200.

Even now that the cost of sequencing a human genome has come down dramatically, the information one gets out of it is not the silver bullet we need to fully understand human biology. It is arguably table-stakes in the long run.
In this primer, I won’t be covering the therapeutics companies themselves. As an analyst, I cover everything but the drugs. I do, however, monitor the activity in the space closely. I just prefer to leave clinical trial analysis to those who specialize there. Instead, I’ll go over the next-gen tools researchers are using to push science forward as well as the ones that have been around a while and are increasingly finding themselves relevant. I’ll also talk about what is happening in diagnostics.
For full disclosure, I’m not directly long any of the names I mention here at the moment except for Twist (which I have written about), but have been in the recent past. Most of the names in these spaces are SMID-cap in nature and extremely volatile, which can be fun to take advantage of if you understand the broader market context.
The 3 Key “Omics”
“Omics” refers to several key areas of study of biology today, and the umbrella term is used for them with increasing frequency because the relationship of each to the others is a key area of study as well. To list them out plainly, the 3 major “Omics” are as follows:
Genomics: What is “written” in your genome
Transcriptomics: What is “expressed” from your genome
Proteomics: The proteins that end up in the body (sometimes a result of the former)
The 3 are highly related to each other. There are more “omes” but for the purpose of investing, these are the ones that matter today because many picks-and-shovels businesses that benefit from increasing research interest in these spaces are public companies today.
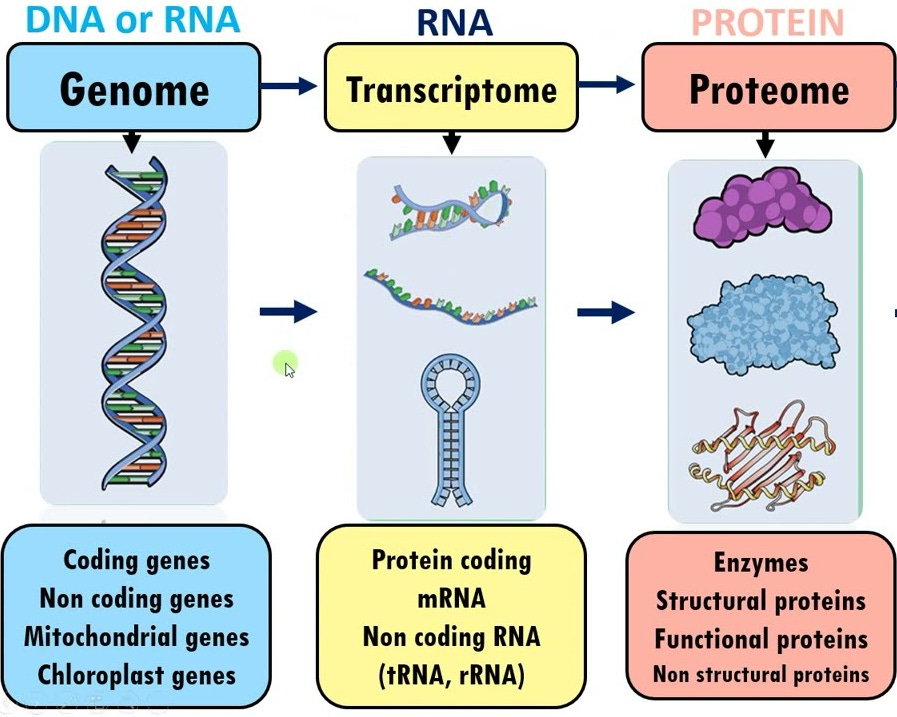
They all matter for obvious reasons, both independently and together. You can “quantify” genomes and transcriptomes down into A/T/C/G, and proteins into combinations of 20 different types of amino acids. Once you have big datasets, you can start to do interesting things with data analytics/ML/AI and start linking specific anomalies to specific diseases. Once you know what to target, you can make better drugs or select better patients.
These anomalies can start anywhere in the chain - perhaps the genome is different in a way it shouldn’t be, or perhaps the cells are under- or over-expressing a gene that leads to bad proteins being created. Sometimes the proteins themselves are the problem - it could have little to do with your genes, after all.
There is also the question of other factors like your microbiome (your gut environment), but this is a more nascent area of science with a lot of complicating factors. Furthermore, most of the research is happening on the first three, which also happen to be the most investable for a public markets investor.
Biased vs Unbiased Tools
One of the key things to know is that it has long been possible to find a single gene or protein present in a sample if you know what you’re looking for. There are a bunch of methods that can do this, but here are a few:
Polymerase chain reaction (PCR): PCR is a reaction that rapidly produces/amplifies a specific segment of DNA into millions/billions of copies to the point that it is visually obvious, either to the eye or a machine.
Enzyme linked immunosorbent assay (ELISA): A reaction that uses antibodies linked to enzymes to detect and measure the amount of a substance in a solution.
Western Blot: Technique that detects a specific protein in a blood or tissue sample. The method involves using gel electrophoresis to separate the sample's proteins.
PCR can effectively detect specific DNA sequences in a sample, and ELISA/Western Blot/flow cytometry/etc. can find specific proteins. These reactions (assays) have been automated inside of systems that take a sample and spit out the relevant data. These are “targeted”, or biased methods.
By contrast, you can use “untargeted” or unbiased approaches to finding genes (ex: Illumina or another sequencer) or proteins (mass spectrometry), but you’ll get a LOT more data (more than you need in certain cases). This nuance matters because the unbiased methods just tell you everything your analytical tool has found in the sample. When per sample cost and turnaround times are big factors, the decision to study samples using biased vs unbiased.
Genes can be read in an unbiased fashion using sequencing instruments
Illumina owns most of the market today in short-read (discussion below)
PacBio and Oxford Nanopore are pioneering long-read sequencing
Proteins can be measured using a mass spectrometer
Thermo Fisher and Bruker are the leaders in research MS with many other players involved as well
It is important to note, however, that mass spectrometers today are unable to read the entire proteome of most samples (it catches the most common stuff, but misses some of the less abundant proteins) - companies have iterated to get us closer but we are not there yet.
Genomics
Genomics was largely a story of Illumina to most investors until a few years ago. Today, however, the landscape is far more evolved, and several companies have reached large enough sizes that we are beginning to see competitive waves.
How Illumina Changed the Game
Remember that pricing curve above? That was practically all Illumina (NYSE: ILMN). Illumina pioneered sequencing-by-synthesis and got it to work in a scalable way. At the time, many were skeptical the company could make it work, but things changed when Illumina bought Solexa and R&D’d its way to a highly successful product. As you saw above, Illumina’s iterations toward Novaseq, the first truly high-throughput sequencing instrument, has been the major driver of the price of sequencing coming down. In a lot of ways, it still is, but at least there is competition forcing things along.
Competition Has (Finally) Arrived
Sequencing is only going to keep getting cheaper - one need not look beyond the fact that several competitors have launched compelling instruments boasting cheaper sequencing than the $550-$600 Illumina had out until last year. The competitive response by Illumina was quick and obvious - a new instrument that could get you to $200.
These have arrived partially by innovation, but also due to the fact that the core patents for Illumina’s sequencing method (sequencing by synthesis) have expired or are expiring. These major competitors are Complete Genomics (BGI), Ultimate Genomics, and Element Biosciences. The first 2 compete most closely in R&D-facing sequencing, whereas Element is going after clinical sequencing (think genomics as a diagnosis).
This is not the full extent of sequencing competition for Illumina in R&D, however. Without overdoing it on the nuance, there are two other forms of competition facing Illumina today:
Long-read sequencing, which is arguably more useful for parsing specific nuances in research related to irregularities across longer gene lengths, is becoming cheaper as well, and is actively competing for share against short-read, where Illumina plays
Additional overlays, such as proteomics, single-cell, and spatial analysis, also compete for funding dollars. Instead of running more samples in a genomics experiment, you could add other data-gathering methods
The above makes it challenging for me to have a strong opinion on Illumina (ILMN) as an investment. I could go on in the form of a deep-dive, but the tl:dr is that forecasting fundamentals, from top- to bottom-line, has never been harder for the company because elasticity of demand is becoming more complicated and sequencing prices are coming down.
Transcriptomics (Single Cell & Spatial)
One of the things you can do on an Illumina sequencer is detect RNA as well. All you have to do is change how you prepare the samples you put in the machine a little. However, the underlying sequencing being done gives you an imperfect RNA dataset in a lot of cases. We didn’t know that for sure until the 2010s, and now we have additional tools to make these outputs more robust.
Bulk Sequencing and its Limitations
When you run a sample through a sequencer today, using the traditional workflow, the activity is called “bulk” sequencing. This is because the information the sequencer is delivering is giving you the DNA/RNA profile of the “average” of the cells in the sample you entered.
However, there is an inherent problem in averages when you think about clinical utility. If you want to diagnose a patient with a rare transcription error, you want the outliers. If you were looking for classrooms in a school that had failing students, how would you get them if the only datapoint you had was the average test score of each class?
How Single-Cell and Spatial Transcriptomics are Changing Science
Companies like 10x Genomics and Nanostring have introduced instruments that add the additional layers of resolution missing from bulk sequencing. Each has developed an instrument that “tags” the cells in a sample in a way that allows a sequencing machine to generate data that identifies the individual ones.
In single-cell experiments, this means you get cell-by-cell information about RNA expression from each cell. In spatial, you can see where genes are being expressed on a tissue sample, effectively giving you a “map” to work from.
Most spatial tools use targeted approaches, however, meaning that you only see what you’re looking for. The exception today is the Visium platform by 10x Genomics, but it currently lacks single-cell resolution, which hinders its utility in finding rare cell types.
Below is a useful visual analogy for the 3 that Nanostring likes to use:

The instruments we have today aren’t perfect, and they’re not cheap (yet) on a per-sample basis. But what we’ve learned from them to date is compelling, and companies continue to iterate on these platforms to make them able to work with more sample types, less sample, and do more interesting things. These companies are highly incentivized to make the per-sample cost of these advanced tools cheaper to allow for larger experiments.
So how are these approaches changing science? There are a few ways:
Single cell analysis allows researchers to identify undiscovered rare cell types and their function with respect to genetic disease.
Both single cell and spatial allow us to better understand the relationship between genomic errors and what gets expressed, as well as how it affects certain surface proteins.
By combining these datasets with protein analysis, researchers can find new drivers of protein creation that may be driving disease. This is somewhat redundant with the first point.
Both approaches could also, in theory, have utility in creating advanced diagnostics that flag these cell types. This is especially likely for spatial, but the path to adoption ahead still looks pretty long.
Proteomics
While genomic and transcriptomic information is certainly very useful, most of why it matters is because of its implications on the proteome. Furthermore, not all proteomic issues are directly a function of the genome. Taken together, a full understanding of changes in the proteome of a patient is theoretically more valuable than genomic information, in a vacuum.

One of the “holy grails” is understanding which parts are genetically-driven and which are not. However, getting all of this information today is elusive to researchers. That said, advances are being made. Companies like Thermo Fisher and Bruker are delivering better Mass spectrometry instruments capable of detecting more proteins, for example. The image above is from Seer, which aims to help companies further advance proteome coverage with its instrument and consumables.

As you try to map the relationship between everything, analysis gets significantly more complex as you add proteins (meaning there are a lot more studies to perform). This means we probably have a decade of wood to chop ahead of us in this endeavor, even as our tools improve.
We’re So Early.
We are early because we don’t even know how to detect all of the proteins in the human proteome. We don’t even know for sure how many there are! We’re still estimating the range.
The “unbiased” approaches like mass spectrometry aren’t quite sensitive enough to capture all of them. The only reason you can still call them unbiased is precisely because you don’t get to choose which proteins the instrument is sensitive enough to find.

The Current Bifurcation of the Proteomics Landscape
We are working with two issues in proteomics today. The first is mentioned above - we don’t really know how many proteins are in the average human proteome. This makes it impossible to know if our unbiased technology is sensitive enough to capture the whole thing. The other is that mass spectrometry does not produce the easiest dataset to marry with genomic information and the workflows are very separate.
The need to more seamlessly integrate proteomic information with the other omics has led to category creation: high-plex targeted proteomics. “Plex” refers to the number of “things” you can analyze in a reaction/experiment/etc. For example, a 30-plex proteomics assay can tell you if any of 30 proteins are present in a sample. In this case, a pair of companies have created antibody panels that can detect thousands of different proteins at once in a way that is compatible with sequencing (“NGS readout”).
There is utility for both mass spectrometry and high-plex technologies in the R&D market. What is likely, however, is that the high-plex benefits from being more flexible logistically. Below is a picture of Thermo Fisher’s Oribtrap Exploris 120 System:

Most mass spec technologies (and all of the best ones) are extremely large systems, making the idea of a benchtop proteomics experiment elusive unless you’re in a dedicated lab that houses them. It’s certainly possible, but step inside a lab and you’ll see how crowded they usually look.
How to Grow Your Omics Tools Company
Omics tools tend to follow a traditional S-curve for fairly unsurprising reasons. The only nuance is that adoption happens in 2 separate markets, and not always at the same time. Biopharma often waits for publications on a topic to inform its decision on whether or not to use a technology. There is even a world where lots of research gets done that has no application to biopharma, making the tech successful in academia but not biopharma.
To illustrate how the growth algorithm works in Academia alone, let’s use a simple sales-rep model with conservative assumptions.

The output is as you’d expect - an S-curve.
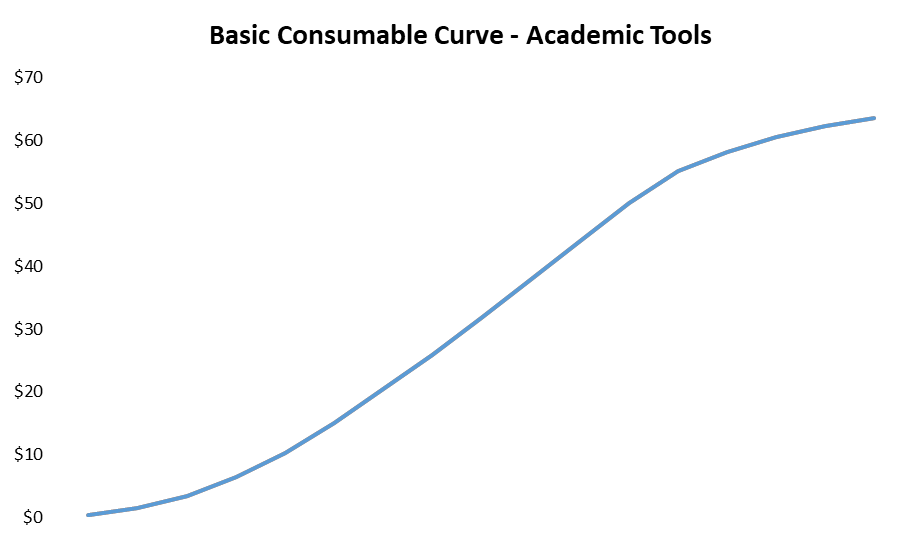
Once you generate a certain amount of interest in academia, biopharma rapidly starts to adopt a technology. This supplements out-year growth, effectively extending the S-curve by adding to it, much like you see in the “second act” of a software company.
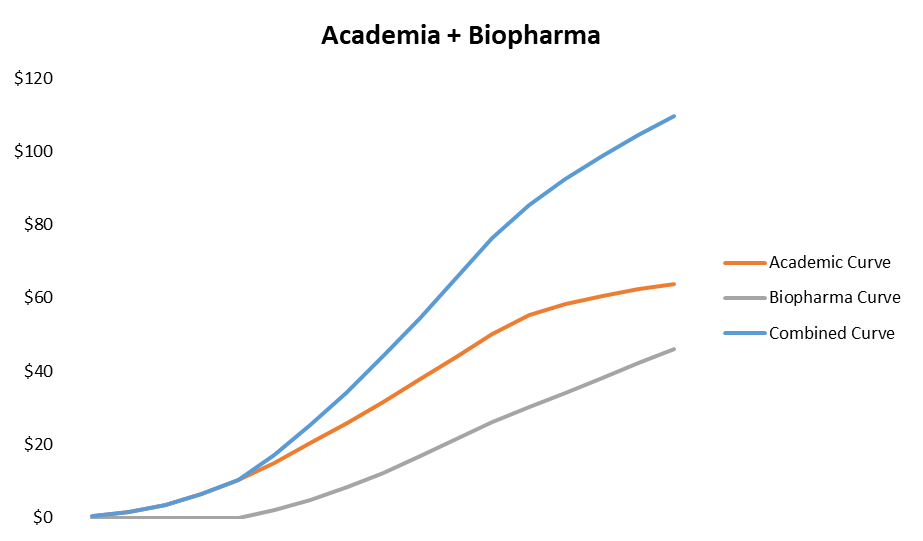
This is just one of many ways the curve could go, but the key takeaway is that you should be wary of any tools company trying to go straight for biopharma first as it usually doesn’t work. Data generation to prove a technology is costly, and academia is a no-brainer place to generate it without an innovator spending its own money.
By contrast, bioprocessing tools have lumpier underlying use cases. The demands of each customer are structurally stepwise until they go commercial. Pretend/assume that a biologic drug makes it all the way through phase 3 to commercial and then fails. For simplicity’s sake, also assume that the number of patients in phase 1 magically necessitates $1M in bioprocessing consumables. The trial patient population doubles in phase 2, and then grows 5x in phase 3 (based on historical clinicaltrials.gov data). The revenue curve would look something like this:
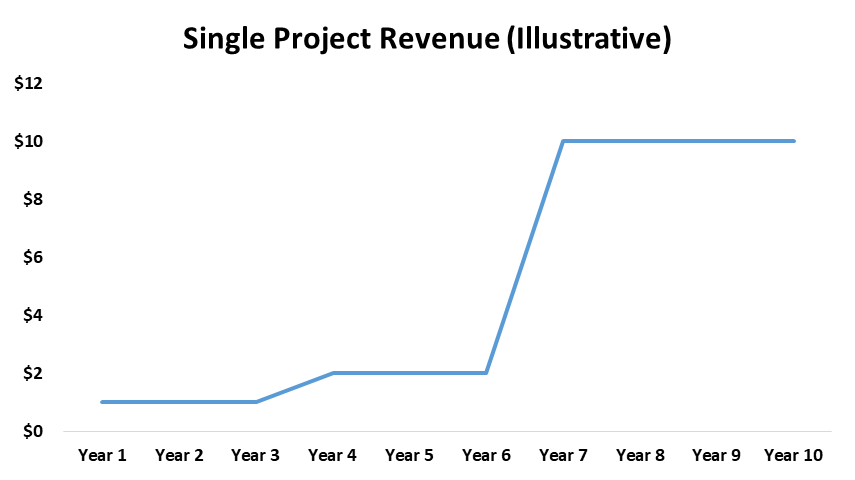
Now assume that there are 10 such projects in year 1, growing 10% a year (so 11 added in year 2 and so forth), with a fixed dropout rate along the way. Stacking the curves on top of eachother, you get something like this:
If you can ignore the likely inaccuracy of the smoothed-out assumptions I set forth here, what you’ll see is a more linear underlying growth pattern for bioprocessing that likely holds true for even the more early-stage technologies over time.
Understanding the difference can help you avoid getting burned by the perception of long-term high-growth in R&D tools when those expectations cool down to reality - things look exponential until they aren’t (and vice-versa if you’re early).
How to Play Omics - Analytical Tools Landscape
If everything above is interesting to you, it is incredibly easy to get direct exposure to the picks and shovels powering the various “Omics” on almost any level of specificity you want. Most of the space went public over the last 5 years, including some of the more nascent technologies thanks to the 2021 craze.
Before I go into the specific companies, I want to point out how related a lot of these spaces are. Broadly, these businesses all rely on a combination of academic and biopharma R&D interest, so the macro of each is similar across the board to the extent the company in question is an R&D tool (if used as a diagnostic, things change a lot). Furthermore, some of the non-genomic tools still have gene sequencing involved in the workflow (transcriptomics, high-plex proteomics).
With that in mind, if you can develop a specific view that a type of experiment is catching on, or that a specific name is undervalued based on near-term issues that get worked out over time, this list should arm you with what you need to capitalize on a new set of growth opportunities.
Genomics & Transcriptomics Picks
The public companies in this universe all either rely on Illumina sequencing or compete with it in some way, so I’m grouping the two together. The public companies in the space, by category, are as follows:
Short-read sequencing:
Illumina (ILMN)
BGI (SHE: 300676)
Note: Several private companies are beginning to compete in this space as well
Long-read sequencing:
Pacific Biosciences (PACB)
Oxford Nanopore (ONT.L)
Single-cell transcriptomics:
10x Genomics (TXG; Flagship product)
Some private companies (sub-scale)
Spatial analysis:
10x Genomics (TXG; subsequent products to single-cell instrument)
Nanostring (NSTG; subsequent product to original nCounter product)
Akoya Biosciences (AKYA; phenotyping only)
Bio-Techne (TECH; ACD product suite, not pure play)
Sample/library preparation:
Illumina (ILMN)
QIAGEN (QGEN)
Twist Bioscience (TWST)
Roche (ROG.SW)
Note: None are pure-play, TWST has the highest mix at ~40% library prep
Of these, I am of the opinion that the most interesting are the long-read and spatial companies. Long-read is simply better data generation than short-read, and thus stands to gain a lot of share from short-read if it becomes cheap enough. Spatial, while nascent, has a lot of theoretical clinical utility. I’ll talk about why this is important in the next section.
Proteomics Shovels
Proteomics is a little easier to play from a picks-and-shovels perspective, thanks to the need for antibodies in a lot of the work getting done.
Research-Grade Antibodies:
Abcam (ABCM)
Bio-Techne (TECH)
Revvity (RVTY)
Note: ABCM is closest to pure-play
High-Plex Proteomics:
OLink (OLK)
Somalogic (SLGC)
Mass Spec:
Large Caps (TMO, BRKR, etc.)
Seer (SEER)
Protein Sequencing:
Nautilus (NAUT)
Quantum-Si (QSI)
Note: VERY NASCENT. Neither has launched a product yet.
I intentionally removed the low-plex part of the market because it is legacy, the tech is commoditized, and I would hesitate to truly group things like ELISA instruments and flow cytometers as real exposure to “omics”. If you want the ELISA exposure, TECH has you covered anyway.
Within this group, I think OLK is the most exciting from a technology perspective, but this could change if protein sequencing becomes a “thing”. Generally, however, it’s easier to own to end market with something like TECH or ABCM.
Applying Omics - Diagnosis & Discovery
While doing experiments is cool, specific applications are what keep a tool in use for the maximum amount of time possible. There are two major categories for this.
The first, as you’d expect, is in drug discovery. Gene sequencing is just one of a large number of tools that found its way into the drug discovery R&D toolkit. Researchers in this field need things that allow them to screen large numbers of cells for specific attributes in parallel. They also want to look for specific traits of cells of interest, among a whole plethora of other things. This piece is fairly straightforward to understand. Some technologies, however, will ultimately make it into what I believe is a much larger TAM - the clinic.
The second, more elusive application of omics tools is diagnosis. Clinicians and companies can, in theory, use some of these tools to diagnose disease or as a way to select a specific therapy for a patient. In the case of genomics, this is already a widespread phenomenon - whole genome (or simpler) sequencing is a popular clinical tool today. This has resulted in another ~$2B in clinical revenues for ILMN over time, still growing in the double-digits today, on top of the ~$2B it was able to reach in research and applied markets.
If other technologies can find themselves with similar clinical utility, they too could partake is what is emerging as a large market. For example, a long-read sequencing company could have a test built on it to identify rare genetic diseases. Below is from a slide from one of the industry players, Guardant, concerning just a few of its end markets:

In theory, genomics inputs would be some percent of this TAM (sequencing/sample prep are cost of goods here).
I won’t go into clinical omics in depth, as I could probably write an entire standalone article about it, but if you’re interested in tracking the space, the larger public companies I’d follow are:
Exact Sciences (EXAS)
Guardant Health (GH)
Natera (NTRA)
Neogenomics (NEO)
Quest Diagnostics (DGX)*
Labcorp (LH)*
* Legacy diagnostic lab companies
Some Exciting Knock-On Effects of Modern Omics Advances
These technologies are all exciting, and many of them are already validated in pretty significant ways. One of the key things that gets lost, however, is that we did not have these technologies 5+ years ago.
This matters a lot because it implies that our understanding of the genetic and proteomic drivers of disease has reached an inflection point during a period of time that began so recently that most drugs being approved and rejected today were discovered without these technologies available.
For example, this paper from 2017 showed that single-cell analysis allowed for the detection of certain error-riddled cells that had a larger hand in aging than others. Those that didn’t created enough noise that bulk sequencing was unable to detect them.

By being able to detect and target these cells, we can better understand what drugs work on which patients, as well as discover novel targets.
One of my favorite pieces of evidence that this technology is transforming our ability to discover drugs is Wyatt McDonnel’s decision to quit 10x Genomics to start Infinimmune in order to use the technology he helped build to discover drugs.

You’d have to think that in order to make a decision like that, you’d need a fair bit of conviction you’d find something interesting, no?
Overall, I expect next-gen omics to drive discoveries in therapeutic areas that we have been largely unsuccessful in to date, such as in neurology. This opens up a lot of potential treatments and cures where there were none before, which could expand the life science universe dramatically as a whole over time. This alone gives me comfort in the next 10+ years of biopharma R&D and the megatrend toward larger molecule drugs as we increasingly seek to correct genetic errors instead of target their outputs.
Challenges/Risks: What Can Go Wrong When Investing in Omics
I personally have been burned investing in omics companies a few times, but have also avoided a lot of mistakes by being a practical thinker. These are some industry-specific risks that are worth knowing about if you plan to give this space a whirl. One of these three is a way I’ve personally been blindsided, and the others are ones I am thinking about as we head toward 2024.
Cost Curve: Price Elasticity is Not Infinite
In academia, there is a lot of price elasticity as technology starts to move below the $1,000-$1,500/sample line. Illumina proved this with genomics. The question, however, is what happens when the technology gets so cheap that a study can run “enough” samples through sequencing to count as “a lot”? To a researcher, is there a big difference between 10,000 samples and 20,000? Maybe, but not if you consider you could use the additional room in your budget to run other analysis on the original 10,000.
Consider the following:
You are applying for a grant to of 1 million dollars of funding to an experiment
It costs $600/sample to run a genome through your Illumina sequencer
It costs and additional ~$1200/sample to run it in single cell
You’ll be more more likely to win the grant if you’re doing “something interesting”
You were originally going to spend $600k on Illumina consumables to run 1,000 samples and the rest on sample prep and other things for the experiment. But now, you find out Illumina costs only $200/sample, and that a new kit at 10x Genomics makes single cell only $600/sample.
You now have a question to answer - would I rather run 3,000 samples instead, or should cut the experiment down to 750 samples and run the whole thing in single cell? What about some combination?
This is oversimplifying, but is actually a key reason why many investors don’t own Illumina today. While lower pricing will most certainly drive more sequencing, will it make up for how much lower the per-sample price is after a certain point? In the example above, a “combination” could be 1,200 samples done with half (600) done in single-cell. In that situation, Illumina would make less than half of what it would when its price was $600/sample.
This can happen in any market, but in a grant-based academic environment, where data generation is king, pricing can go from being a huge enabler of adoption to a headwind very easily. Competition will force you to those price points, so you’re likely damned if you do, damned if you don’t when the market reaches that level of maturity.
Core Lab Dynamics
An interesting complexity of academia as an end-market is the concept of a core lab. Many universities, despite having many different individual labs, will often use a hub-and-spoke model to consolidate its adoption of expensive capital equipment. Here’s an image from Westlake University:

The above represent “hubs”; imagine every other, smaller lab at Westlake as if it were at the other end of a “spoke”. Westlake has set it up so that its researchers have a place to send their samples for analysis depending on what they are doing. This means that researchers can apply for a grant and run experiments without needing to do most of the heavy lifting on data generation. Your favorite professor can simply send a sample and get back a large data file to analyze. Most major universities do this in one way or another.
This is a cool dynamic, but also an important risk as a technology moves along the adoption curve. 10x Genomics was a good example of this in 2022 - growth in 2021 was massive, as core labs across the country fully adopted the tech and maxed out their usage of the Chromium instruments they had. However, researchers liked the technology enough that they got their own Chromium systems to cut down on wait times and add flexibility to their smaller labs. This made it hard to model how much usage the average instrument got. It had stayed stable for several years above $100k/system, but these new “halo” users were probably at around half of that. Once every core lab has an instrument, and is maxing out usage, it is hard to grow as fast because the next leg of the story is more decentralized and cannibalistic.
It’s hard to quantify when this will happen - the number of active core labs is tricky to pin down, but also doesn’t matter because it’s hard to figure out how many instruments each core lab owns or wants to own.
In the above example, 10x Genomics had installed ~3,500 instruments globally by the end of 2021, the year before consumable revenue growth fell off a cliff. 54% revenue was from the US that year, having trended down from 61% in 2017. 30-40% of revenue was to biopharma over the same period.
This implies that academic core labs only needed about 1,200 instruments to fill all of the core lab demand in the US. Everything placement after that was likely somewhat cannibalistic. For reference, there are about 2,800 4-year universities in the US. Only some percent of those do a meaningful amount of research.
If you are early enough to a technology, you won’t have to worry about this risk, but if you are a long-term holder, this dynamic creates a fundamental wrinkle that can be hard to time or anticipate.
The Academia Funding Engine & NIH - Could the Omics Space be Headed for Trouble in 2024?
I’ve been writing about this one for a while on Twitter. This is a risk to the entire academic end-market. The NIH, which is said to be responsible for funding about a quarter of all academic research in one way or another, has to apply for funding from the US government every year under the HHS umbrella.
Here’s what that funding has looked like over the last couple of decades:
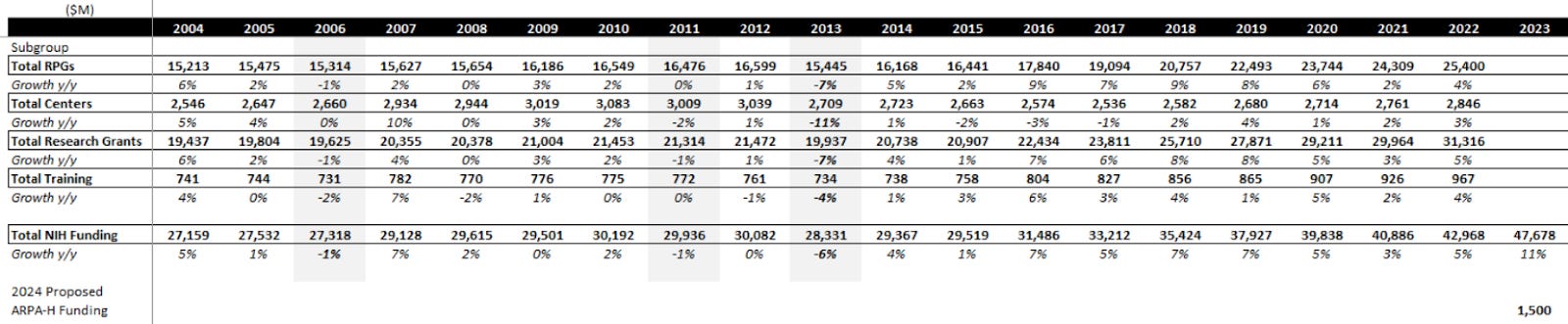
One new addition was ARPA-H this year, which added a fair bit to funding for biologic moonshot projects. For FY24, Biden’s proposal in March was for $51B and $2.5B for ARPA-H, which together implies NIH funding grows ~9% (7% ex-ARPA-H), well above the long-term average of 3-4%. However, the debt ceiling issue may be putting a massive wrench in this plan. These numbers are what was proposed, not what has been given.
The government is currently working out how to limit total federal spending as part of the debt ceiling negotiations, which requires bipartisan support, meaning compromises have to be made. These compromises will be made on discretionary spending, a category that 100% of the NIH falls into.
To make things scarier, Roll Call reported a few weeks ago on the GOP’s latest proposal, which attempts to make cuts to all discretionary programs except defense:

In 2023, the NIH was ~41% of HHS's $112B discretionary budget authority. HHS is 54% of the category you see above. If you assume that only half of the $60B cut happens (some type of compromise) and is proportionally distributed to labor, HHS, and education, that’s $16B cut out of HHS and $6.6B cut from NIH specifically vs 2023 numbers. This would be a 14% y/y decline, the largest in NIH history, and one of only 3 cuts since the 90s. There are a lot of unknowns today, but a 14% headwind to 25% of academic research takes 3.5% out of an end-market that usually only grows about that much annually. In my mind, this is a growing tail risk in a period where academic market growth has been running hot in the US.
The other scary part is endowment funding for research is probably running tight as well given negative market returns last year (assuming most university investment offices had similar performance in aggregate). Combined with the VC/alts meltdown, there are lots of reasons to think we could have a bumpy couple of years for academia.
Offsetting this are things like DoD budgets increasingly moving toward biologic research. While the academic end-market might face some scary headwinds, I think the way to navigate this is to own assets that align with the cutting-edge of research, as I think those likely prove to be the most insulated. It’s a shame the best ones so expensive…

This is a volatile space, so things won’t always be this way. If you’re willing to pay up for the growth, I think a basket of the “cutting edge” names would like something like this:
TXG
OLK
PACB
The rest have things to prove. While a bad year would obviously hurt the cutting-edge basket, I’d be willing to bet that the others on that list suffer significantly more fundamentally, which could have knock-on effects in terms of future dilution. Perhaps a counter-intuitive pair trade? Could be easy to balance the multiple factor in other areas like medical devices.
I think the more obvious move, however, is to stay on the sidelines until this is resolved, and if the risk materializes, expect things to sell off and create valuation opportunities.
A Note to Long-Term Investors
As I mentioned in the introduction, I currently don’t hold any of the names mentioned above (except for Twist, which is sequencing-adjacent, given >40% of sales come from next-gen sequencing tools like library prep kits).
There are reasons for this. As much as I love to own the picks and shovels of huge trends, omics tools are a category of investments that one needs to re-underwrite more frequently than others. In a single year, the number of credible competitors, per sample pricing, and adjacent technologies competing for budget dollars could all change in ways you can’t model today. The major ways to play the space are all single-product stories, which turns a lot of investors off.
Long-term means a lot of things to a lot of people, so I’ll be clear: these are not set-it-and-forget-it stocks. If you have a 3-year horizon, and can invest in smaller companies, this is an excellent space to follow. This space a specialist’s heaven, but generalists who understand the ABC’s of how academia and biopharma work at a high level shouldn’t be afraid to get involved when valuations present possible opportunities. If you are looking for the next Thermo Fisher, however, you probably won’t find it here anytime soon.
One of the hallmarks of the large-cap tools space is pricing power. TMO/DHR/MTD/etc. all raise prices 1-2% in a normal year, and were able to flex those numbers as high as 5% during 2022.
With negative per-sample pricing of such a magnitude as Illumina/10x/PacBio, and a lack of historical evidence on what the true pricing elasticity curve looks like in different end markets, it’s almost impossible to accurately underwrite the P’s and Q’s as an investor more than a couple years out, and the companies themselves don’t exactly have better historical data to work with than we do. What you can do is underwrite the most conservative pricing you can think of, and assume some kind of elasticity that can be sanity-checked. Oftentimes, the medium-term IRRs look good, especially given the high margins some of these companies tout at scale.
This could change 5+ years from now, in a world where the genome costs $10 to sequence and nobody notices if ILMN and its peers all want to raise the flow cell pricing to make it $10.50 in a given year. However, pricing is a #1 concern for customers today given the absolute level it’s at. I have similar concerns about the diagnostics segment of the market, and there are a whole host of other things you have to navigate to be a strong investor in the space.
Conclusion
I hope you found this primer helpful. I’m sure I didn’t do the category perfect justice, as it is incredibly complex and I am in the business of simplifying things. If you like single-product companies, omics is as good as it gets, unless you’re brave enough to invest in medical devices.
As always, feel free to message me with feedback/questions on Twitter or via email.
Fantastic write up
super interesting, thank you for this amazing write-up!